I've been curious for a bit what types of tools are available to make formal input-output claims about neural networks. After a bit of reading it seems like the predominant approach is a modified version of Branch-and-Bound (a common algorithm used to solve integer programming problems). I'll attempt to explain how a basic version of this works here.
The Setup
The motivation for formal verification on neural networks seems to have come from the field of adversarial/robust machine learning. The main finding of adversarial ML is that if you take a model—let's say an image classifier—and optimize a correctly classified input to shift logits toward a separate label, you can produce adversarial inputs that get misclassified with high confidence but are a small $\epsilon$ away from the original input:
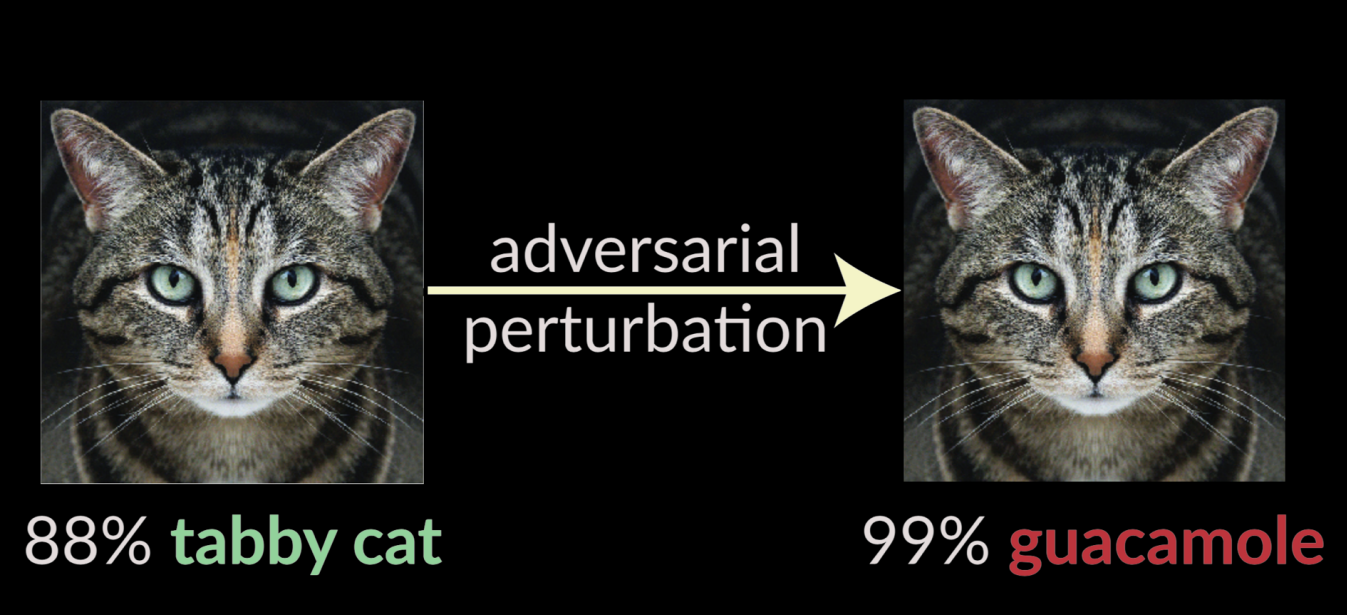 (slide from this Nicholas Carlini talk)
(slide from this Nicholas Carlini talk)
This motivated tools that could take a particular input and prove the (non-)existence of an input within the space of nearby (distance $\le \epsilon$) inputs that flips the label.
We can formalize the epsilon ball around the given input $x_0$ as
where the $l_\infty$ norm is often used because it means this set is a literal box in input space, which makes specifying constraints later easier.
Let's limit ourselves to an MLP with ReLU activations $f_\theta$ as our network to analyze. As I understand it, it's not too hard to generalize to other activation functions (though I gather that softmax + transformers are hard).
We can now formalize this problem: (dis)prove the existence of an $x\in B_\epsilon(x_0)$ such that our network $f_\theta$ gives adversarial class $t$ a higher logit than correct class $c$ when evaluated on $x$: $f_\theta(x)_t > f_\theta(x)_c$.
This is NP-Complete!
This is NP-Complete. There's even a polynomial-time reduction from 3-SAT to this1
The intuition for why this is true is that it's quite hard to do any sort of global analysis with the nonlinearities of the ReLUs. If there are $n$ neurons in our network, that gives a worst case of $2^n$ possible ReLU patterns over our input space (each ReLU slicing space with a hyperplane, with it active on one side and inactive on the other).2
If you fix each neuron $a$ in a network to be either active ($a>0$) or inactive ($a=0$), then your network becomes fully linear, and you can use typical linear programming methods, such as the simplex method, to solve that sub-problem easily.
Let's model that.
Variables
At each layer $\ell$, we need variables to represent the networks pre-activations (before the ReLU is applied), $z^{(\ell)}$, as well as the activations themselves $a^{(\ell)}$. The inputs will be $x=a^{(0)}$.
Constraints
We need to bound our inputs inside the epsilon ball (this is where the $l_\infty$ norm making the epsilon ball an epsilon box makes things easy—this can be done component-wise):
We need to constrain pre-activations to the previous layer's activations:
And we'll need to add constraints based on whether each neuron $a^{(\ell)}_i$ is active or inactive. If it's active, we tie it to the pre-activation (which can't be negative):
And if it's inactive, we simply set it to zero:
Note that these constraints only allow network activations that actually arise for some point in the input space $B_\epsilon(x_0)$. But, since we're forcing an arbitrary pattern of ReLU activation, we're almost definitely not covering all inputs in the input space.
Objective
The objective is simply the difference in logits between the logit for target class $t$ and correct class $c$:
This is now ready to be handed off to an LP solver to find the configuration which maximizes $M$.
If it finds a configuration where $M>0$, then there exists an $x\in B_\epsilon(x_0)$ that will flip the label! If we get $M\le 0$ or there are no valid solutions, this tells us that, for this particular ReLU pattern, there are no inputs in $B_\epsilon(x_0)$ that flip the label.
In order to make claims about all possible ReLU patterns, we need branch-and-bound.
Branch-and-Bound
Fix some order of neurons, then we can construct a binary tree where each level corresponds to the decision of whether that neuron is active or inactive. Notice that the leaf nodes correspond to fully decided ReLU patterns, whereas the internal nodes still have some neurons where we haven't fixed them to be active/inactive yet. A network with $n=4$ neurons would yield a tree like this:
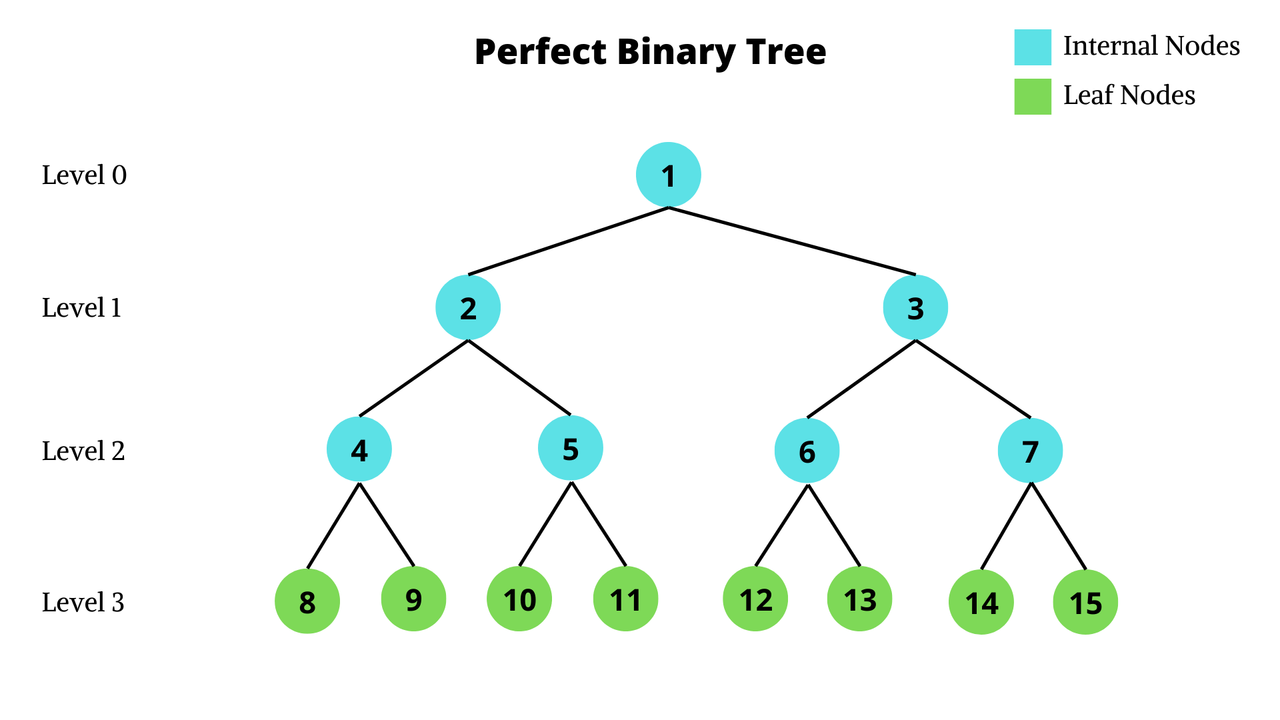
Theoretically, we could enumerate all $2^n$ ReLU patterns (corresponding to all the leaf nodes) and run an LP solver on each one. This would give us a correct result, but would take ages.
Instead, we're going to solve relaxed versions of the problem at internal nodes that will allow us to prune entire subtrees, dramatically speeding up the process.
Remember how the internal nodes have some set of neurons that we haven't fixed active/inactive yet? We're going to relax the problem by allowing those neurons to take values they technically can't take in exchange for being able to allow them to take all of their possible values (with ReLU active and active) in one LP solve.
Since those neurons are allowed to take any valid value as well as other values, this gives us an upper bound on $M$ for that sub-tree (no descendants of that node can have a larger value of $M$). If the bound we get for $M$ is less than $0$, we can happily prune that entire subtree with the knowledge that no ReLU pattern contained within can yield an adversarial example with $M > 0$.
Note that if the bound we get for $M$ is greater than $0$, this is not a guarantee that there is an adversarial example within the subtree that actually achieves that bound3, as it's possible that this value for $M$ is only achievable when using the relaxed values.
We'll talk about how the relaxation works in a moment, but taking that as given, here's the algorithm:
Starting from the root, explore the tree by solving LP relaxations. When the result is negative, prune that subtree. If you reach a fully fixed solution with
$M>0$, terminate (you've found an adversarial solution). Else, continue exploring the current frontier.
I'm being deliberately vague here about how you explore the tree (DFS, BFS, etc.) and how you choose which neurons to branch on. While any choice that explores everything is valid, some methods will find adversarial inputs more quickly.
Triangle Relaxation
To understand the relaxation of activations, let's start by looking at the ReLU function, $a(z)=\max\{0,z\}$:
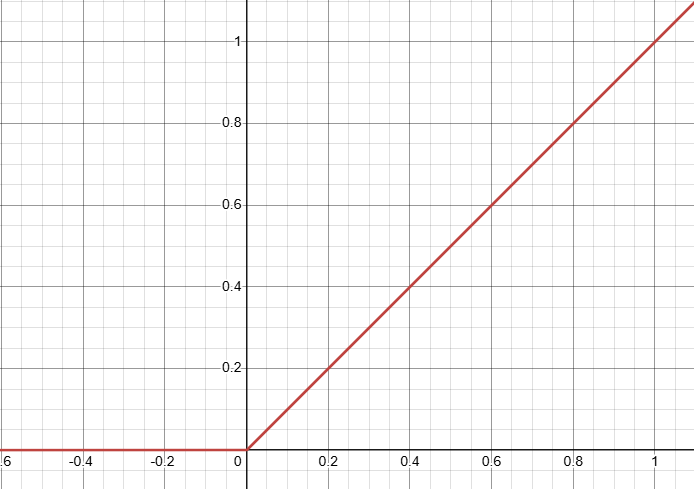
We're going to assume we have some (potentially quite loose) bounds $[l, u]$ on the value that the pre-activation $z$ can take: $l\le z\le u$.4
We want to find the smallest convex set5 that contains this function. That looks like this:
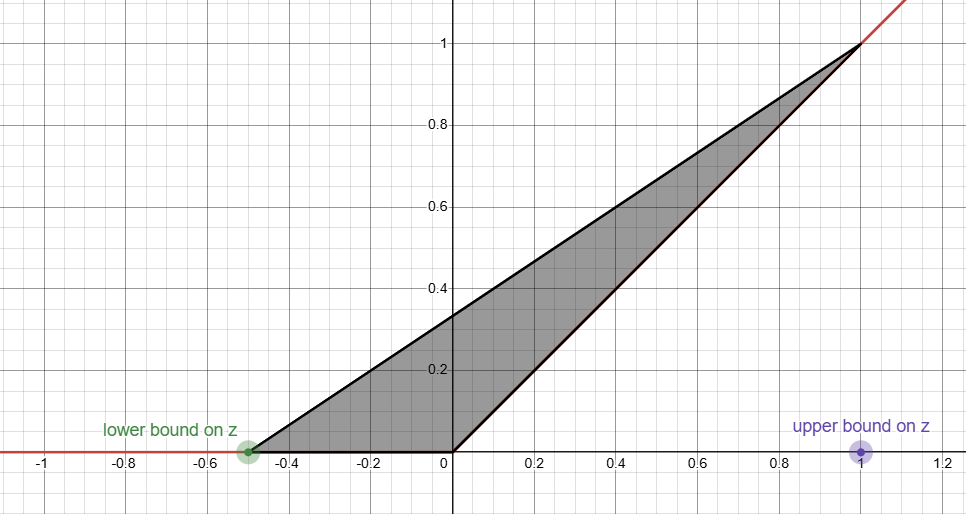
Understand why it's called the triangle relaxation?
Since this is a convex set, it's easy to represent this with inequalities (one per side):
And that's it! Instead of being forced to pick active/inactive for every neuron, we can relax some of them, allowing them to take values in this triangle.
Other Stuff
Lot of other stuff I want to look into at some point!
- how to handle non-ReLU activations?
- see CROWN
- What's SOTA?
- How good are solvers so far? how big of networks can they handle?
- small-to-medium CNNs
- applying to a transformer is harder - softmax is harder to relax, cross-position interactions are hard, discrete inputs.
- Can you make claims about things that don't look like the typical epsilon ball robustness claim?
- Theoretically you can choose any input space you can define and make claims about any linear function of activations. The number of unstable neurons (neurons whose upper and lower pre-activation bounds straddle
$0$) does grow as your input space gets bigger.
- Theoretically you can choose any input space you can define and make claims about any linear function of activations. The number of unstable neurons (neurons whose upper and lower pre-activation bounds straddle
See appendix I of this paper.
In practice, the true number of distinct ReLU regions in an epsilon ball grows much more slowly. This is the reason that branch-and-bound solvers are somewhat feasible in practice, as the true depth of the branch-and-bound tree is the number of neurons that are unstable (active in some parts of the epsilon ball and inactive in others). For neurons that are stable (active/inactive over the entire epsilon ball), we don't need make a decision in the branch-and-bound tree.
In other words, the leaf nodes of that subtree may all yield $M<0$ or be infeasible.
Not going to talk about how you get these bounds. This paper describes the very simple interval bound approach. CROWN and the alpha-CROWN follow-up are fancier methods. I'm sure there are many more.
Convex because that's what we can represent with inequalities and we want the smallest possible one to get a tighter bound.